This section deals with creating gainful insights. This is where the "arts" coming into the sciences. All the code for this section can be found in this file.
Remember we had created a wordlist of type PlaintextCorpusReader. This uses the datastructure of a nested list.
PlaintextCorpusReader type is made up of a list of fileids, which are made up of a list of paragraphs, which is in turn made up of a list of sentences, which is in turn made up of a list of words.
words(): list of str
sents(): list of (list of str)
paras(): list of (list of (list of str))
fileids(): list of (list of (list of (list of str)))
>>Albums = wordlist.fileids()
>>Albums[:14]
['JayZ_American Gangster_American Dreamin.txt',
'JayZ_American Gangster_American Gangster.txt',
'JayZ_American Gangster_Blue Magic.txt',
'JayZ_American Gangster_Fallin.txt',
'JayZ_American Gangster_Hello Brooklyn 20.txt',
'JayZ_American Gangster_I Know.txt',
'JayZ_American Gangster_Ignorant Shit.txt',
'JayZ_American Gangster_Intro.txt',
'JayZ_American Gangster_No Hook.txt',
'JayZ_American Gangster_Party Life.txt',
'JayZ_American Gangster_Pray.txt',
'JayZ_American Gangster_Say Hello.txt',
'JayZ_American Gangster_Success.txt',
'JayZ_American Gangster_Sweet.txt']
In this section, lets investigate the use of basketball language in Jay Z's lyrics. Go ahead and save all the album titles by typing in Albums = wordlist.fileids().
Notice that JayZ_ text appears before each of the filenames. To get this prefix out of the filename, we extracted the first five characters, using fileid[5:].
[fileid[5:] for fileid in Albums[:14]]
We are ready to start mining the data. So let's do a simple analysis on the occurence of the concept "basketball" in JayZ's lyrics as represented by the list of 40 terms that are common when we talk about basketball.
basketball_bag_of_words = ['bounce','crossover','technical',
'shooting','double','jump','goal','backdoor','chest','ball',
'team','block','throw','offensive','point','airball','pick',
'assist','shot','layup','break','dribble','roll','cut','forward',
'move','zone','three-pointer','free','post','fast','blocking','backcourt',
'violation','foul','field','pass','turnover','alley-oop','guard']
Lets reduce our investigation of this concept to just the American Gangster album, which is the first 14 songs in the corpus. We do that by using the command Albums[:14]. Remember that Albums is just a list data type, so we can slice it, to its first 14 indexes.
The following code converts the words in the basket ball concept to lowercase using w.lower(), then checks if they start with any of the "targets", that is, each of the words in the basketball_bag_of_words, using the command startswith(). Thus, it will count words like turnover, alley-oop and so on. All this is enabled by NLTK's built in function for Conditional Frequency Distribution. You can read more about it here.
>> cfd = nltk.ConditionalFreqDist(
(target, fileid[5:])
for fileid in Albums[:14]
for w in wordlist.words(fileid)
for target in basketball_bag_of_words
if w.lower().startswith(target))
>> cfd.plot()
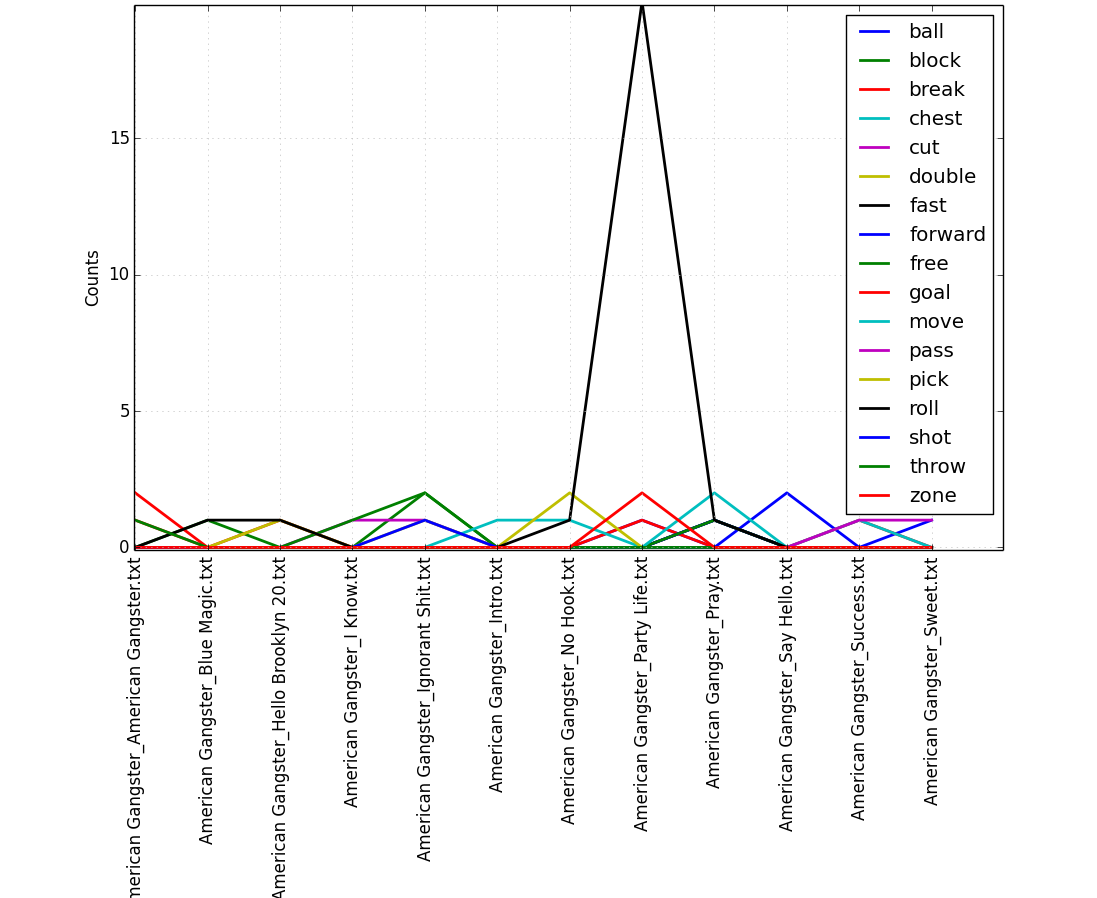
From the plot we see that the basketball term "roll" seems to be used extensively in the song Party Life. Let's take a closer look at this phenomenon, and determine if "roll" was used in the "basketball" sense of the term. To do this, we need to see the context in which it was used. So, lets build a concordance.
The first thing I want to do is to create a corpus that only contain words from the American Gangster album.
>> AmericanGangster_wordlist = PlaintextCorpusReader(corpus_root, 'JayZ_American Gangster_.*')
>> AmericanGangster_corpus = create_corpus(AmericanGangster_wordlist, [])
Building a concordance, gets us to the area of elementary information retrieval (IR)1, think, basic search engine. So why do we even need to "normalize" terms? We want to match U.S.A. and USA. Also when we enter roll, we would like to match Roll, and rolling. One way to do this is to stem the word. That is, reduce it down to its base/stem/root form. As such automate(s), automatic, automation all reduced to automat. Most stemmers are pretty basic and just chop off standard affixes indicating things like tense (e.g., "-ed") and possessive forms (e.g., "-'s"). Here, we'll use the most popular english language stemmer, the Potter stemmer, which comes with NLTK.
Once our tokens are stemmed, we can rest easy knowing that roll, Rolling, Rolls will all stem to roll.
>>porter = nltk.PorterStemmer()
>>stemmed_tokens = [porter.stem(t) for t in AmericanGangster_corpus]
>>for token in sorted(set(stemmed_tokens))[860:870]:
print token + ' [' + str(stemmed_tokens.count(token)) + ']'
dummi [1]
dump [1]
dure [1]
each [1]
earlob [1]
eas [1]
easel [1]
easi [1]
easili [1]
eat [5]
Now we can go ahead and create a concordance to test if roll is used in the basketball (pick and roll) sense or not.
>>AmericanGangster_lyrics = IndexedText(porter, AmericanGangster_corpus)
>>AmericanGangster_lyrics.concordance('roll')
in my veins like a pisces The Pyrex pot rolled up my sleeves Turn one into two l
dinner s now turn in to Breakfast I only roll Lexus to Hug your road I love your
ut I do lift Weight like I m using roids Rolls Royce Keep my movements smooth whi
lefty Gangster effortlessly Poppa was a rolling stone its in my ancestry I m in
babe I got a slick mouth you might wanna roll with me I m on her bra strap she
ike CASINO They should pay me for some B roll Takin G strolls through the ghee to
n lets keep it smooth This that shit you roll up like a little tight J to Sip ya
her s afro as momma taps her toes as she rolls her jays and my poppa just left th
Based on the context, you can decide if the word "roll" is used in a basketball sense. This is really where the "art" of the word "Arts and Sciences" comes to play in Data Science and NLP.
1. Some of this content has been adapted from Dan Jurafsky's Stanford CS124 class