You know, Caesar is a Dead White Male. How come we can have his stupid picture but we can't have genuine heros such as Turing and Snowden? -bh

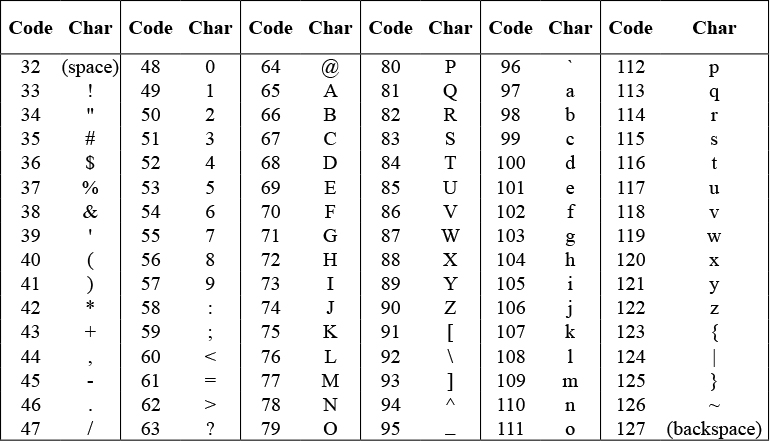
Computers store keyboard characters (capital and small letters, punctuation marks, space, digits, symbols, and so on) as numbers called Unicode. This table shows the Unicode for some of the keyboard characters:
The unicode of block reports the number that is used for a particular character:
 reporting '97'")
The unicode as letter block reports the character that a given Unicode number represents:
 as letter reporting 'A'")
unicode of and unicode as letter blocks. Try changing a word into Unicode, telling the Unicode to a friend, and then having them change it back into a word.Why do we see characters like = ? @ # ^ * { or ~ ?
You can safely assume that shifting any set of text characters a reasonable distance will result in a set of printable characters, which may include non-alphanumeric (not letter or digit) characters.
For example, if we use a shift of 4 to encrypt:
Invasion of Normandy is on 6 June 1944
it becomes:
Mrzewmsr$sj$Rsvqerh}$mw$sr$:$Nyri$5=88
What if your decrypted text is missing some letters?
If you copy your encrypted message with a method other than by using copy and paste (for example, by writing it by hand or typing it into a phone), some characters may disappear from your message. This is because some of the Unicode characters after 126 are printing characters that symbolize things like "delete." These characters won't get displayed in Snap!, so you can't copy them by hand, but if you use copy and paste, Snap! knows they are there. In Take It Further exercise A, you can develop a method of encryption that avoids this problem.
